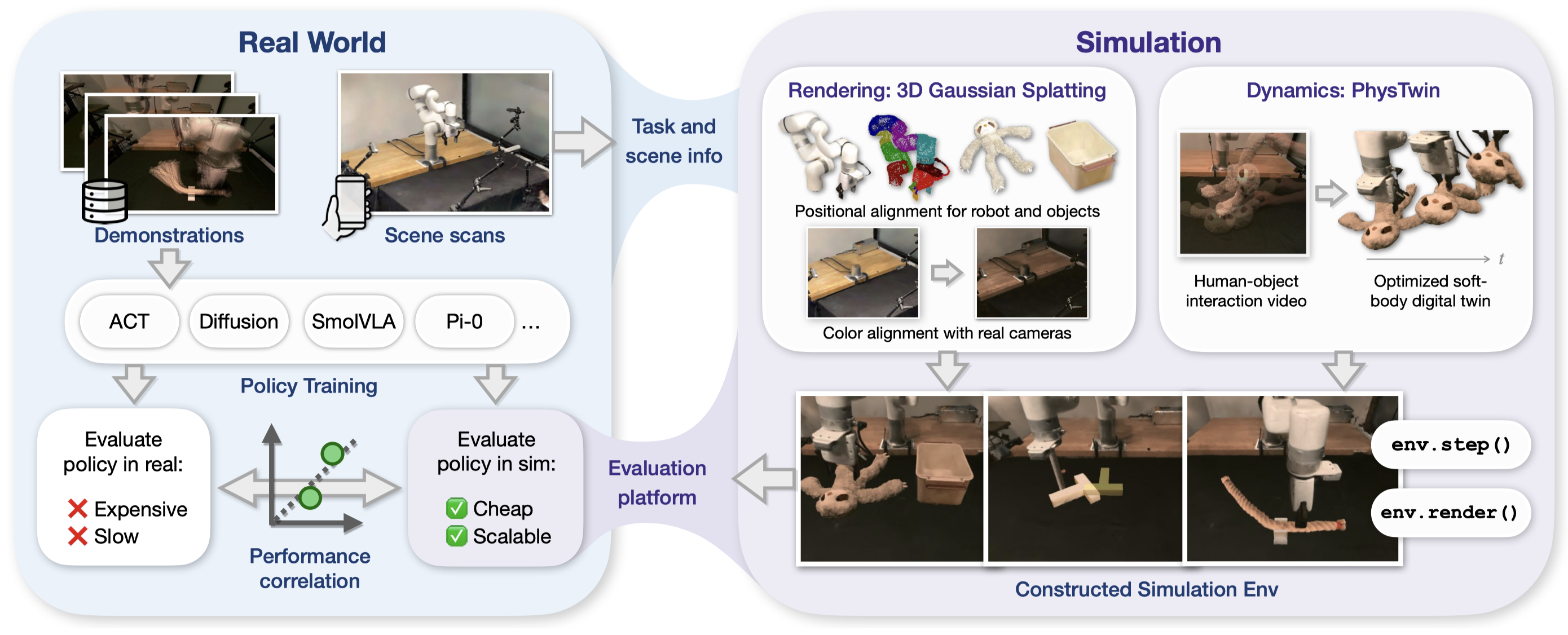
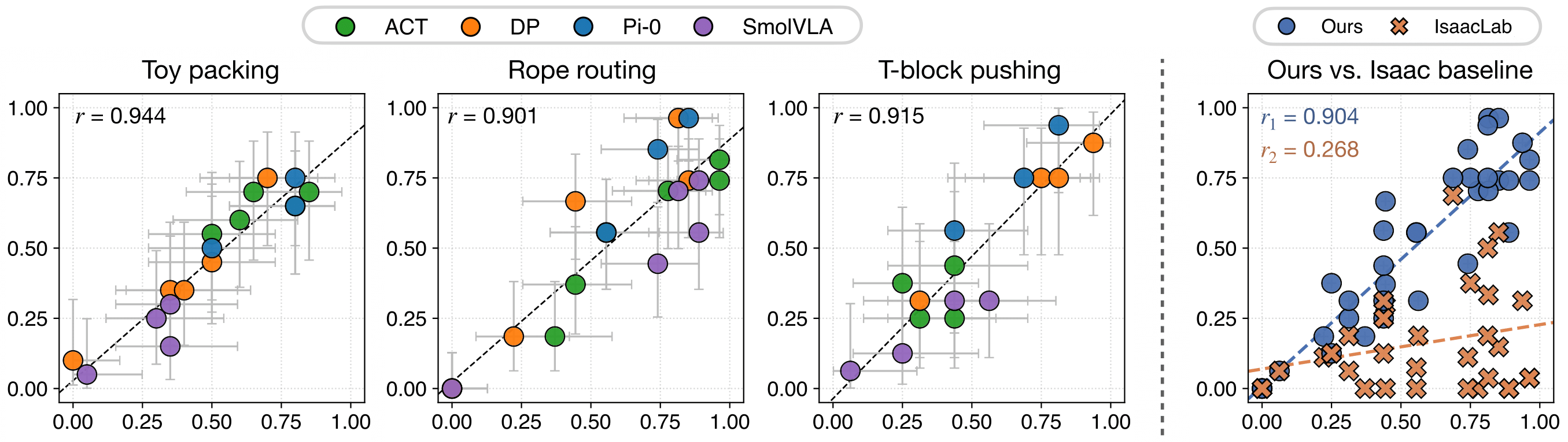
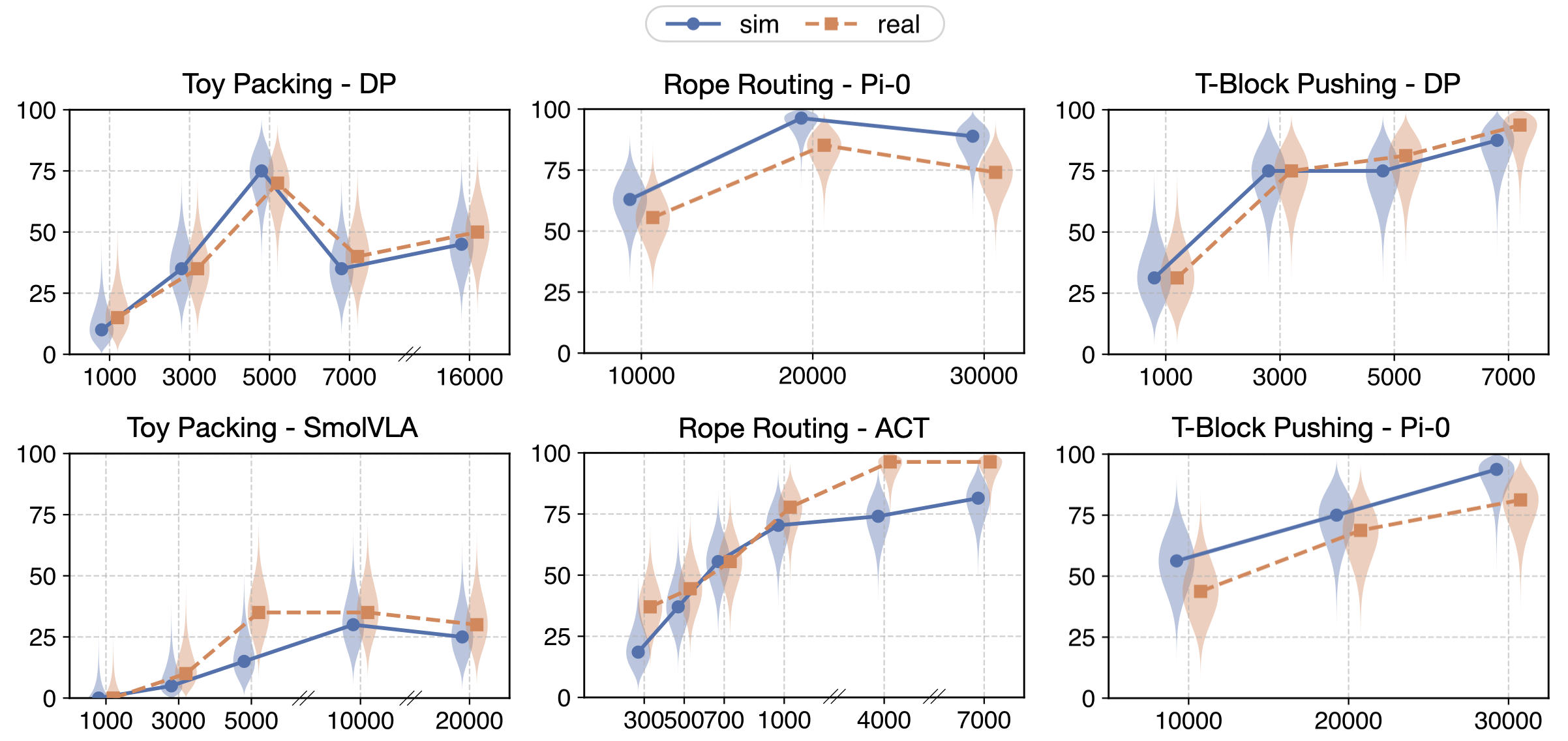
Policy evaluation in sim environments constructed from real world, using Gaussian Splatting for rendering and soft-body digital twin for dynamics.

Interactive Gaussian Visualization
Reconstructed GS simulation environment. Best viewed on computers.
Teleoperation in Sim
The reconstructed environment can be controlled with keyboard and puppeteer arms, with online rendering.
Teleoperation in sim with keyboard (left) and GELLO (right). Videos 5x speed.